im sure youve felt it too -- talking to any LLM, responses tend to be quite generic, no?
2510.22954
↗ arxiv.org
"Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)". this paper systematicised the evaluation of all the models to show that model results are converging (same prompt -> very similar responses)
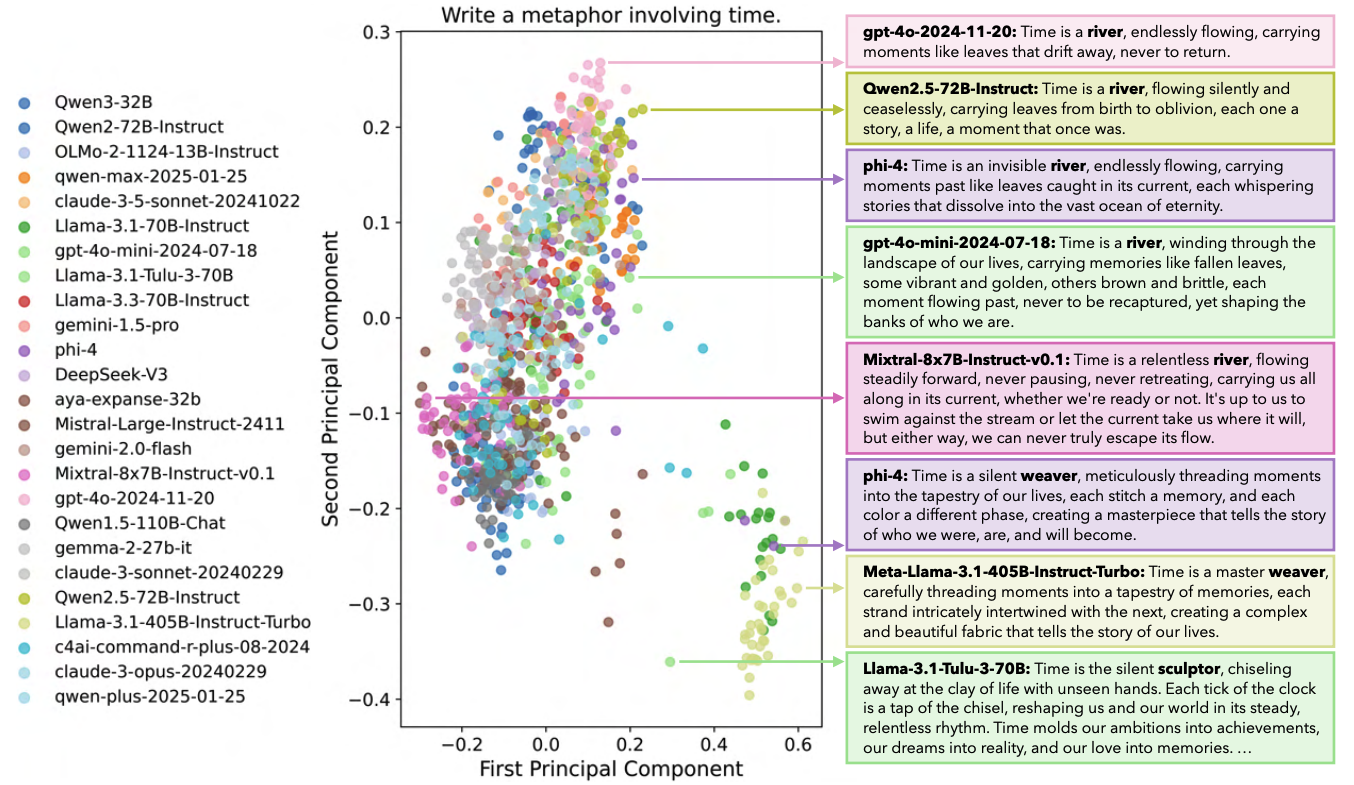
- new dataset, "INFINITY-CHAT": a large-scale dataset of 26K real-world open-ended queries spanning diverse, naturally occurring prompts
- the Artificial Hivemind effect: (1) intra-model repetition, where a single model repeatedly generates similar outputs, and, more critically, (2) inter-model homogeneity, where different models independently converge on similar ideas with minor variations in phrasing. this is not just a matter of LLM "tuning" to the dataset, but a more fundamental property of the models.
- what's causing this? training on synthetic data, insufficient diversity in training data
implications:
- model selection: if it's true that we are seeing some sort of ensembling / collapsing of model choices, it may imply it matters less to base model picks on its "general quality of responses" (obv there are still differentiators like speed, model size, use case and context, tone etc.)
- edge computing, specialised use cases: yes these foundational AI companies want "AGI", "general" intelligence -- but for industry applications imo, folks want specialised models (e.g. healthcare keywords, SWE trained models). to me it sounds like opportunity to train context-specific models, even your own mini-local one with your own data.
- lack of creativity, bias, responsible ai, etc.: all encoding similar biases, all representing a majority voice, all thinking the same way. cliches from head to tail.